Portfolio de Projet : Modélisation et Gestion d'une Base de Données Relationnelle pour les Données Géographiques Françaises
1. Présentation du Projet
Ce projet consiste à modéliser et manipuler une base de données relationnelle contenant des informations sur les régions, départements, et communes françaises, en intégrant des données historiques issues du site de l'INSEE. L'objectif est de construire une base de données en 3NF, de l'enrichir avec des données démographiques, et de mettre en place diverses méthodes pour manipuler et interroger cette base, notamment à travers l'utilisation de triggers, vues, et procédures stockées dans PostgreSQL.
2. Modélisation de la Base de Données
a. Structure de la Base de Données
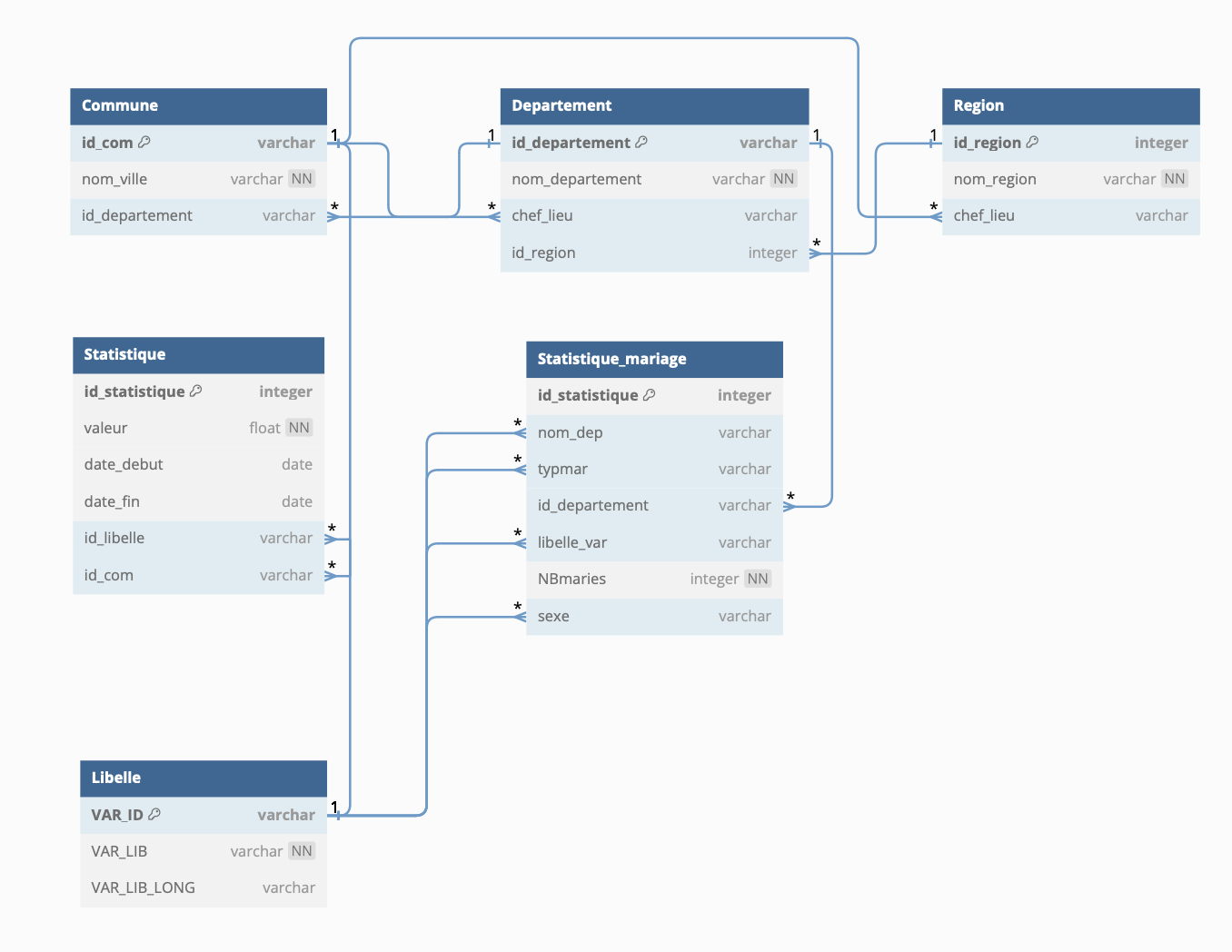
La base de données est composée de trois entités principales : régions, départements, et communes. Chaque entité est reliée par des clés étrangères pour garantir l'intégrité des données. Le modèle respecte la Troisième Forme Normale (3FN) afin d'éliminer les redondances et assurer l'efficacité des requêtes.
Voir le code source- Régions : Chaque région a un identifiant unique et contient des informations comme le nom et la population.
- Départements : Chaque département appartient à une région et possède un chef-lieu (commune).
- Communes : Chaque commune appartient à un département, avec des informations comme son nom, son code postal, et sa population.
b. Données Importées
Les données de base ont été importées à partir de fichiers CSV fournis par l'INSEE. Pour importer rapidement de grands volumes de données, nous avons utilisé la commande COPY de PostgreSQL, avec l'aide de la librairie Python pandas pour le traitement des fichiers CSV.
3. Importation et Manipulation des Données
a. Population des Communes
Dans un premier temps, nous avons importé la population des communes pour les années disponibles. Cette étape implique la lecture des séries historiques de la population, ainsi que l'enrichissement de la base de données avec ces informations.
b. Statistiques de Mariages
Nous avons également intégré des données régionales et départementales concernant les mariages en 2021. Ces données ont été importées et structurées de manière à faciliter les requêtes d'analyse démographique.
4. Création des Vues et Procédures Stockées
a. Vues
- Vue des populations par département : Affiche la population totale par département pour une année donnée.
- Vue des populations par région : Permet de consulter la population totale des régions en fonction des départements qui les composent.
b. Procédure Stockée pour le Calcul des Populations
Une procédure stockée a été écrite pour calculer et mettre à jour automatiquement la population des départements et des régions à partir des données des communes. Cette procédure est appelée lors de l'ajout ou de la mise à jour de la population d'une commune.
5. Triggers et Automatismes
a. Verrouillage des Tables REGIONS et DEPARTEMENTS
Afin de protéger l'intégrité des données, nous avons utilisé des triggers pour interdire les modifications directes sur les tables des régions et départements. Cela empêche toute opération INSERT, UPDATE, ou DELETE non autorisée.
b. Mise à Jour Automatique de la Population
Un trigger a été ajouté pour mettre à jour automatiquement la population des départements et des régions chaque fois qu'une population de commune est modifiée. Ce mécanisme permet d'assurer la cohérence des données et d'automatiser les calculs.
c. Ajout de Nouvelles Années de Recensement
Un trigger permet d'ajouter de nouvelles données de recensement chaque année. Lorsque de nouvelles populations de communes sont ajoutées, la population des départements et des régions est automatiquement recalculée.
6. Requêtes et Analyses
- Liste des départements d'une région donnée : Permet de consulter les départements qui appartiennent à une région spécifique.
- Liste des communes de plus de X habitants dans un département donné : Affiche les communes ayant une population supérieure à un seuil donné pour un département spécifique.
- Région la plus/moins peuplée : Permet de trouver les régions les plus et les moins peuplées, en fonction des populations des départements qui les composent.
7. Analyse des Performances
a. Plan d'Exécution (EXPLAIN)
Nous avons utilisé l'outil EXPLAIN de PostgreSQL pour analyser le coût d'exécution des différentes requêtes. Cela nous a permis d’optimiser les jointures et les stratégies de tri, particulièrement lors de l'interrogation de grandes tables comme celle des communes.
b. Indexation
Nous avons créé des index sur les attributs les plus fréquemment utilisés dans les requêtes, notamment sur la population des communes. Cela a permis d'accélérer les sélections et les jointures.
L’analyse des performances montre une optimisation efficace grâce à l’utilisation de Hash Joins et de scans séquentiels parallèles. Les tables volumineuses comme commune (34 990 lignes) et statistique met en évidence un temps d’exécution réel impressionnant de 2,254 ms. L’architecture de la base en 3NF favorise des jointures rapides et une intégrité des données.
8. Transactions et Niveaux d'Isolement
Dans le cadre de la gestion des transactions, nous avons testé les transactions SQL avec différents niveaux d'isolation pour garantir l'intégrité des données.
9. Coût de Développement et Outils Utilisés
- Langage utilisé : Python pour le traitement des fichiers CSV et l'interaction avec PostgreSQL.
- Base de données : PostgreSQL pour sa robustesse et ses fonctionnalités avancées.
- Temps de développement : Environ 7 jours pour la construction de la base de données, 2 jours supplémentaires pour les triggers, vues et procédures stockées.
10. Perspectives d'Amélioration
- Amélioration des requêtes avec l'utilisation de materialized views.
- Ajout d'autres indicateurs démographiques pour enrichir l'analyse.
- Développement d'une interface graphique ou d'une API RESTful pour une interaction plus simple avec la base de données.